In 2019, we participated in the Shared Task organized by Lancaster University and Fortia Financial Solutions as part of the 2nd Financial Narrative Processing (FNP) Workshop series.
“Title Detection” was one of the two shared tasks proposed on Financial Document Structure Extraction. The objective of this shared task was to classify a given text block, that had been extracted from financial prospectuses in pdf format, as a title.
Built on a CNN-based architecture, our best performing model scored 97.16 %, a percent less than the winning model.
Some of the improvement measures, such as hyper-parameter tuning, weight initialization, are discussed in our paper.
Causality in Finance data, a thread
Data states facts but it provides little to no knowledge regarding how these facts are materialized. While financial analysis depends heavily on factual data, the ability to explain data variability is what makes the analysis effective.
The challenges posed by financial narratives are at the heart of a lot of discussions within the finance industry. As an NLG provider with a specialized focus on Financial Reporting, Yseop is often faced with the need to deliver a relevant mapping of events, indicators, and facts, making causality one of our main research topics.
Our contribution to the FinTOC 2019 shared task provided us with a wonderful opportunity to meet with Mahmoud El-Haj who chair organized the FNP 2019 workshop at NoDaLiDa Conference in Turku, Finland. Mahmoud and Paul Rayson, from Lancaster University, started the Financial Narrative Processing (FNP) workshop series, with the first edition of the workshop being held at LREC 2018 in Miyazaki, Japan.
They kindly accepted to associate us with the 2020 occurrence of the upcoming FNP workshops to be held at the 28th International Conference on Computational Linguistics (COLING’2020), Barcelona, Spain on 12 December 2020.
And a new Shared Task begins: FinCausal
Yseop will be organizing the Financial Document Causality Detection Task and release the FinCausal Dataset associated with that task.
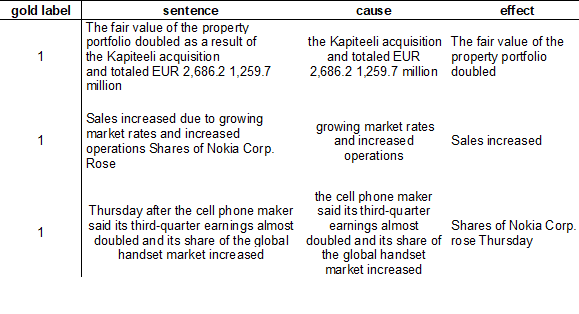
This Shared Task aims to develop an ability to explain, from external sources, the reasons why a transformation occurs in the financial landscape, as a preamble to generating accurate and meaningful financial narrative summaries.
Its goal is to evaluate which events or which chain of events can cause a financial object to be modified or an event to occur, regarding a given external context. This context is available in the financial news, but due to the high volatility of such information, mapping an external cause to a given consequence is not trivial.